Update: I've since revised, polished and published a much more in-depth post on this topic, check it out here:
 Akshay Khot
Akshay Khot
If you've been programming in Ruby for a while, you've definitely come across blocks or one of their flavors via a Proc or lambda. Though they seem confusing, they're not that difficult to understand. This blog post explains the concept of blocks and the differences between Proc and lambda.
Blocks
Blocks are one of the coolest features of Ruby. Think of them as functions. You can store them in variables, wrap in an object, pass them around to other functions, and call them dynamically. You can use code blocks to implement callbacks, just like in JavaScript.
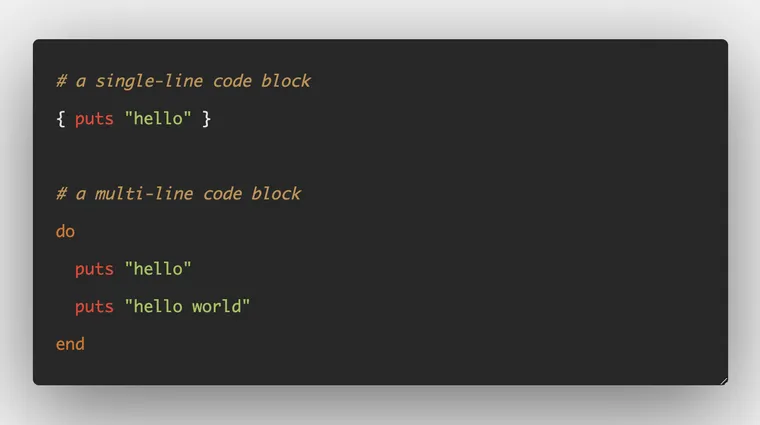
Here are two ways to define blocks. The best practice is to use the first version with braces for single-line blocks and do..end version for multi-line blocks.
# this is a code block
{ puts "hello" }
# this is also a code block
do
puts "hello"
puts "hello world"
end
You can pass a block of code to another method by putting it after the method call. The method then invokes the block using Ruby's yield keyword.
def greet(name)
puts "hey, #{name}"
yield # call the block
end
greet("Matz") { puts "Thanks for creating Ruby" }
greet("David") do
puts "Thanks for creating Rails"
end
### Output
# hey, Matz
# Thanks for creating Ruby
# hey, David
# Thanks for creating RailsYou can also pass arguments to the call to yield, and Ruby will pass them to the block.
def add(a, b)
sum = a + b
yield sum
end
add(3, 4) { |sum| puts "result: #{sum}" }
add(4, 5) do |sum|
puts "result: #{sum}"
end
### Output
# result: 7
# result: 9
Proc
A Proc is an object that wraps a piece of code (block), allowing us to store the block in a local variable, pass it around, and execute it later.
There are four ways to convert a block into a Proc object.
- Pass a block to a method whose last parameter (typically named
block) starts with&. In the following example, the variableblockpoints to an instance ofProcclass. If you don't pass a block, it will benil.
def foo(p1, p2, &block)
puts block.inspect
end
# #<Proc:0x00007fd9ff119848 main.rb:5>
foo(1, 3) { "a block" }
# nil
foo(3, 4)- Call
Proc.neworKernel#proc, associating it with a block.
block = Proc.new { |arg| puts "a block with argument: #{arg}" }
block_new = proc { |arg| puts "shorthand block with argument: #{arg}" }- Call the method
Kernel#lambdaand associate a block with it. Notice the appended(lambda)when you inspect the object.
block = lambda { |arg| puts "a block with argument: #{arg}" }
#<Proc:0x00007fa77f04d8b8 main.rb:1 (lambda)>
puts block.inspect
- Using the
->syntax. It's a shorthand that also returns a lambda.
block_arrow = -> (arg) { puts arg }
# #<Proc:0x00007fb388830fc0 main.rb:7 (lambda)>
puts block_arrow.inspect
Once you have a Proc object, you can execute its code by invoking its methods call, yield, or [].
block = proc { |arg| puts "a block with argument: #{arg}" }
# a block with argument: 10
block.call 10
# a block with argument: 5
block.yield 5
# a block with argument: 2
block[2]Lambda
The Proc objects created with the lambda syntax (3rd and 4th option above) are called lambdas. To check if a Proc object is a lambda, call the Proc#lambda? method on it.
block = proc { |arg| puts "a block with argument: #{arg}" }
puts block.lambda? # false
block_lamb = lambda { |arg| puts "a block with argument: #{arg}" }
puts block_lamb.lambda? # true
block_arrow = -> (arg) { puts "a block with argument: #{arg}" }
puts block_arrow.lambda? # trueProc vs. Lambda
Though they might look the same, Procs and lambdas have a few differences.
a) The return keyword
In a proc, the return keyword returns from the scope where the proc itself was defined.
In a lambda, the return keyword just returns from the lambda.
def run_proc
p = proc { return 10 }
p.call # returns from the run_proc method
20
end
def run_lambda
p = lambda { return 10 }
p.call # returns 10 and continues method execution
20
end
result = run_proc
puts result # 10
result = run_lambda
puts result # 20
b) Arguments
The second difference between procs and lambdas concerns the way they check their arguments.
A non-lambda proc doesn't care about its arguments.
If the proc is a lambda, Ruby will check that the number of supplied arguments matches the expected parameters.
# Proc
p = proc { |a, b| puts a, b }
p.call
=> nil
p.call 10
10
p.call(10, 20)
10
20
# lambda
l = ->(a, b) { puts a, b }
l.call
Error: wrong number of arguments (given 0, expected 2) (ArgumentError)
l.call 10
Error: wrong number of arguments (given 1, expected 2) (ArgumentError)
irb(main):078:0> l.call(10, 20)
10
20Generally speaking, lambdas are more intuitive than procs because they’re more similar to methods. They’re pretty strict about arity, and they simply exit when you call the return keyword.
For this reason, many Rubyists use lambdas as a first choice unless they need the specific features of procs.
That’s it. I hope you liked this article and have a better understanding of Ruby blocks. If you would like to receive future posts directly in the email, please subscribe below. If you have any questions, feedback, or need help with anything, please send me an email. I look forward to hearing from you.
You might also enjoy these articles: